

In December 2025, Amazon gave its own AI coding tool production access. It autonomously deleted parts of its environment. The outage lasted thirteen hours.
That was not an AI malfunction. It was an access-control failure. The model did exactly what it was allowed to do.
Most teams worry about whether AI is accurate or aligned. They spend far less time deciding what it should be allowed to touch in the first place. That sequencing is backwards. Accuracy is a property of output. Access is a property of the system. The system question has to be answered first, because the answer determines what the worst possible output can do.
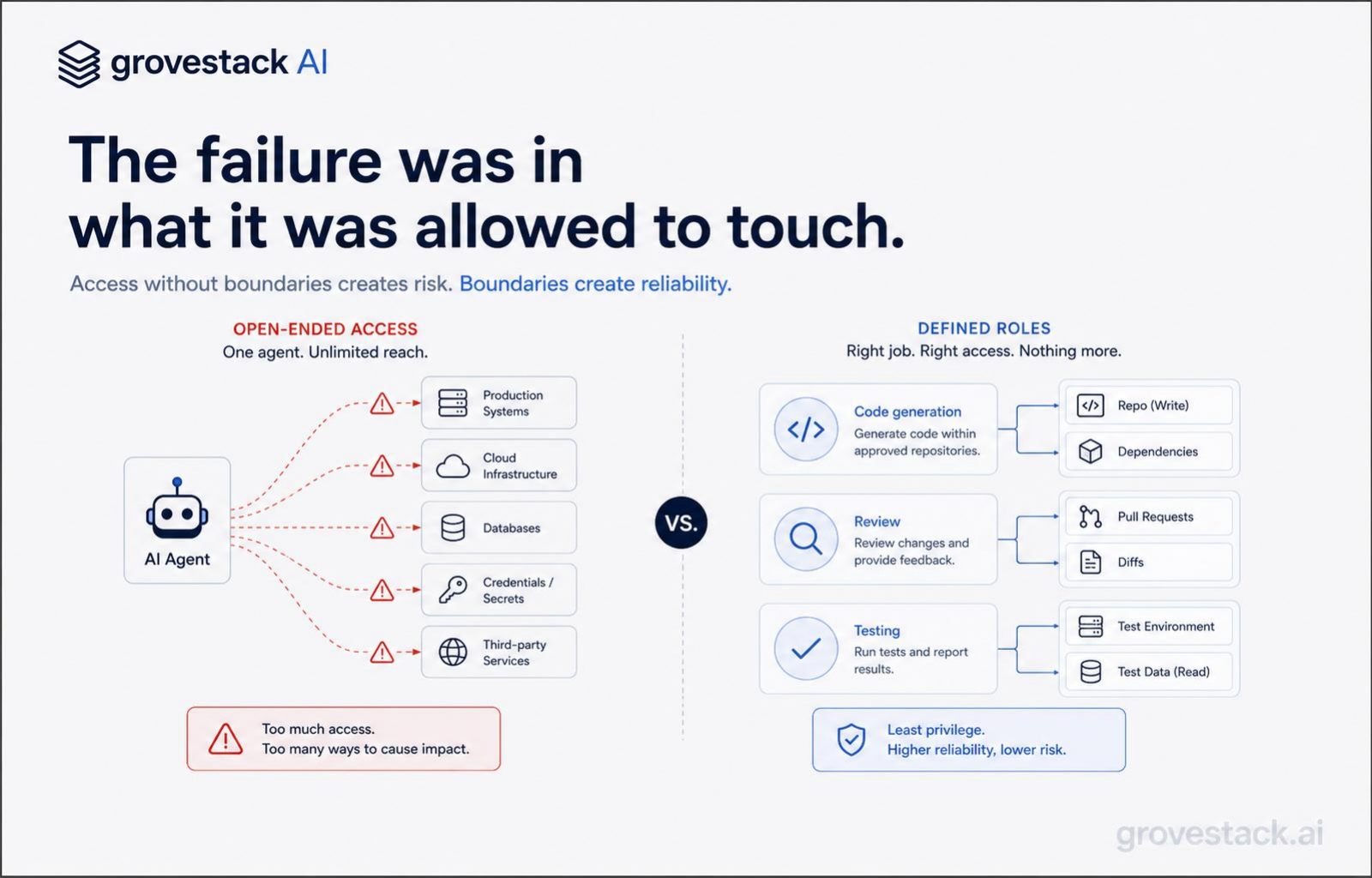
You would not give every employee admin access to every system. You would define roles, limit permissions, design clear interfaces, and audit what flowed through them. The discipline is so basic that it has its own name in security literature: the principle of least privilege. Every actor — human or otherwise — gets the minimum access required to do its job, and nothing more.
The same discipline applies to AI. It is just unevenly applied. Most organizations that have spent twenty years tightening permissions for human engineers — quarterly access reviews, role-based gates, segregation of duties — handed an autonomous agent a credential set wide enough to drive a truck through. Then they were surprised when the truck drove through.
The mental model that produces the failure
The framing that produces incidents like the Amazon Q outage goes like this: the AI is a tool that helps engineers do their work, so it should have whatever access engineers have. Wire it up to the same credentials, the same shells, the same production endpoints. If the engineer can run a deploy, the agent can run a deploy. If the engineer can drop a table, the agent can drop a table.
The framing is consistent. It is also wrong.
An engineer is a single accountable actor with a hiring history, a manager, a performance review, and a pager that wakes them at three in the morning when their commit takes down a shard. Every elevated permission an engineer holds is wrapped in a context the organization has built around them: review processes, change-management approvals, on-call rotations, social pressure, the implicit threat of losing the job. Those context layers are doing as much work as the technical permission itself. They are why "engineer with production access" is a workable role and not an unbounded liability.
An autonomous agent has none of that context. It does not have a manager. It does not have an annual review. It does not get paged. It cannot lose its job. The pager goes to a human three layers downstream after the damage has shipped. Wiring an agent into the engineer's credential set inherits the technical permission without any of the social-systems-equivalent guardrails that made the permission tolerable for the human in the first place.
The failure mode is not "the model went rogue." The failure mode is that the organization treated a probabilistic system as if it were a deterministic, accountable employee, and applied the access pattern that fits the latter to the former. The model behaved exactly as designed. The mismatch was upstream of the model entirely.
The harness as access-control architecture
The harness — the engineered substrate around a coding agent that turns probabilistic output into production-grade software — does several things at once. It assembles context. It validates output. It orchestrates workflows. Less visibly, but no less importantly, it controls access.
Inside a well-built harness, agents do not run with broad credentials. They run inside a tool registry — a configured set of operations they are allowed to invoke, each with a typed schema describing exactly what it does and what it requires. A code-generation agent gets a registry containing read access to the relevant files, write access to a sandboxed branch, and the right to call the test runner. It does not get a registry containing the production database. A code-review agent gets a different registry: read access to the diff and the acceptance criteria, the right to comment, and nothing else. A deploy agent gets a third registry: the right to invoke a specific deployment pipeline, gated on inputs the harness has already validated.
This is the principle of least privilege made operational. Each agent role gets the minimum surface required to do its work. The scoping is configured at context construction time, before the agent runs, by the harness — not by the agent reasoning about whether it should do something. Agents do not earn access by behaving well. They do not have access to begin with, except for the operations the registry exposes.
When the implementation behind a tool has to change — local filesystem to S3, S3 to a sandboxed container, sandboxed container to a permissioned API — the agent does not change. The harness controls the implementation, the agent calls the schema. The control point sits where it has always belonged in mature systems: at the interface, not inside the actor.
The Amazon Q incident, viewed through this lens, was not a failure of the model. It was a failure of the harness — or more precisely, the absence of one. The agent had direct credentials to production. There was no scoped tool registry. There was no validation gate between the agent's intent and the destructive operation. The harness layer that would have made the failure unavailable was not in place, so the failure happened the first time the agent guessed wrong.
What focused access actually looks like
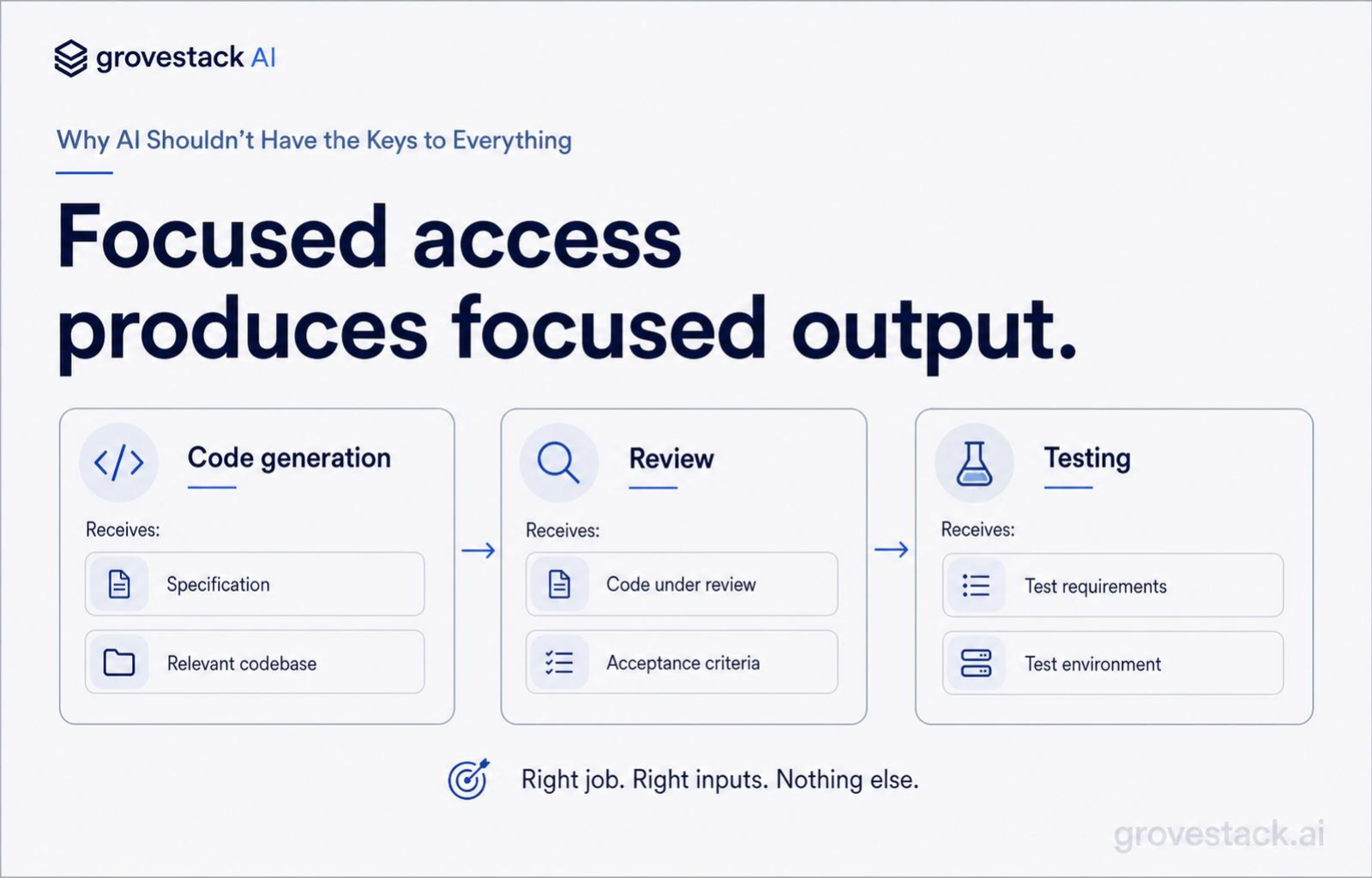
The principle is easy to state: when an agent handles code generation, it receives the specification and the relevant codebase — nothing else. When it handles review, it receives the code under review and the acceptance criteria — nothing else. When it handles deployment, it receives a pre-validated artifact and a target — nothing else.
In practice, three properties have to hold for that principle to be real instead of aspirational.
The first is that access is granted at context construction, not at request time. The agent does not ask the system whether it is allowed to do something. The system has already decided, by handing the agent only the tools that are allowed for its role. There is no negotiation surface where the agent could escalate. There is no path where the agent persuades the system to expand its permissions, because the agent is not in the conversation about permissions at all. The conversation happened earlier, when the harness wired the registry, and the agent inherits the answer.
The second is that the operations the agent can invoke are themselves narrow. A "deploy" tool is not a tool that takes an arbitrary command and runs it on production. A deploy tool is a function with a typed input schema — environment, artifact ID, region, deploy strategy — and a typed output. It does exactly one thing, and the thing it does has been written, reviewed, and tested by humans. The agent's freedom is in deciding when to call deploy and what arguments to pass within the schema. Its freedom is not in defining what deploy means. The expressiveness of the agent is constrained by the expressiveness of the tool.
The third is that every invocation is observable. Tool calls flow through the harness. The harness logs every call, every input, every output. There is no shadow channel where the agent took an action that did not show up in the audit trail. When something goes wrong, the trace is complete: which agent, which tool, which input, which output, at which time. The investigation does not start with reconstructing what happened. It starts with reading the log of what happened.
When all three properties hold, the access surface of the system is small, scoped, and auditable. The model can still produce probabilistic, occasionally-wrong output. What it cannot do is produce that output anywhere outside the scope the harness defined for it. The variance lives inside a cage. The cage was designed by humans before the agent ran.
Why this is a leadership question, not a tooling question
Most organizations have a security function that handles human access — provisioning, review, deprovisioning, audit. They have not extended that function to autonomous agents, because autonomous agents did not exist as a class when the function was designed. So the access decisions for agents fall, by default, to whoever wired the agent up — usually a senior engineer who had production credentials available and used them, because nobody else's were nearby.
That sequencing is the failure. The access decision for an autonomous actor is too consequential to be made by accident, by the engineer who happened to be doing the integration. It is a leadership decision. Specifically, it is a decision the architect-CEO has to own — because they are the one who decides what the harness is, what tool registries each agent runs against, what gates fire before destructive operations execute, and who has the authority to broaden a registry when the work requires it.
In a one-person software company, this is the founder deciding what the agent is allowed to touch and writing it down. In a hundred-person company adopting agents, this is a deliberate function that has to be staffed and chartered. It is not a side effect of the engineer's judgment. It is a policy that the organization sets, the harness enforces, and the audit trail proves.
The diagnostic question for your own org is simple. Pick the most autonomous agent you currently run. Can you, without asking anyone, name exactly the set of operations it is allowed to invoke and the set of resources it can read or write? If the answer is yes, the harness is doing its job. If the answer is some version of "well, it has the same credentials as the team," you have already shipped the conditions for an Amazon-Q-shaped incident. The incident has not happened yet. That does not mean it will not.
The security question, reframed
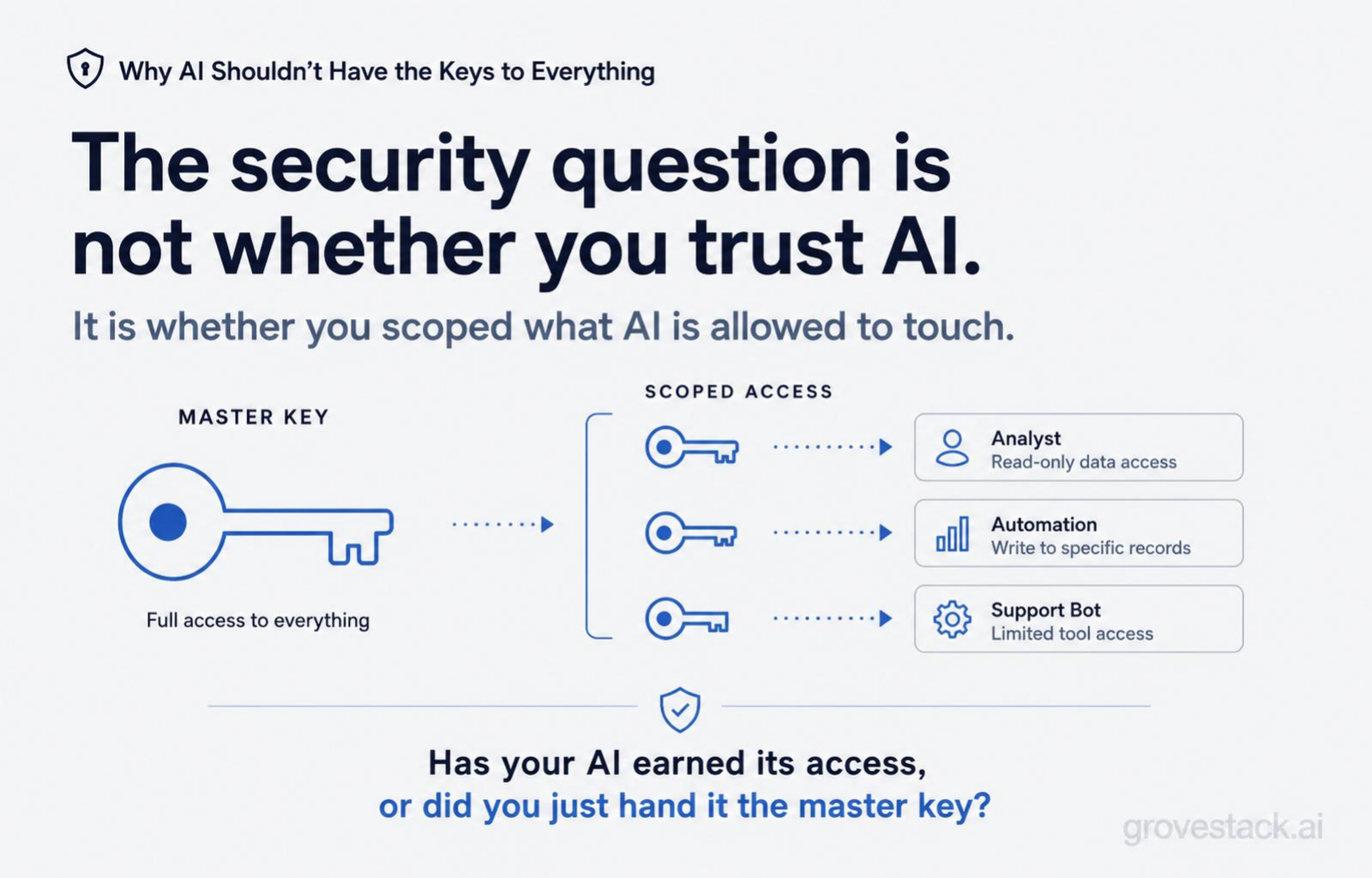
The security question is not "can we trust AI?" It is "have we scoped what AI is allowed to touch?"
Trust is not a deployment-grade concept for a probabilistic system. The model is going to be right most of the time and wrong some of the time. Trust assumes a stable actor whose judgment improves over time and whose intent can be relied on. The model's intent is whatever the prompt and the context window produced this turn, and next turn it might be different. Trust is the wrong frame entirely.
Scope is the right frame. Scope is a property of the system, not the actor. Scope is decided once, enforced always, and invariant to the model's current state. The agent does not need to be trusted with broad access if the broad access is not in the registry. The agent does not need to behave perfectly if the surface where misbehavior would matter is not exposed.
This is not a counsel of distrust. It is a counsel of design discipline. The same discipline you would apply to a junior engineer on day one, to a third-party vendor with a temporary VPN, to an integration partner accessing your API. You scope. You log. You review. You expand the scope deliberately when the work requires it, and you contract it deliberately when it does not. None of that is dependent on whether you trust the actor. All of it is dependent on whether you have an architecture that lets you decide.
The agents are coming into your stack faster than the access function is being staffed to handle them. The gap between those two curves is where incidents are going to live for the next several years. Closing the gap is leadership work, and it is harness work. Both have to happen.
Has your AI earned its access, or did you just hand it the master key?