

If your AI strategy includes "prompt engineering," you are investing in a tactic.
The organizations getting reliable output invested in a system.
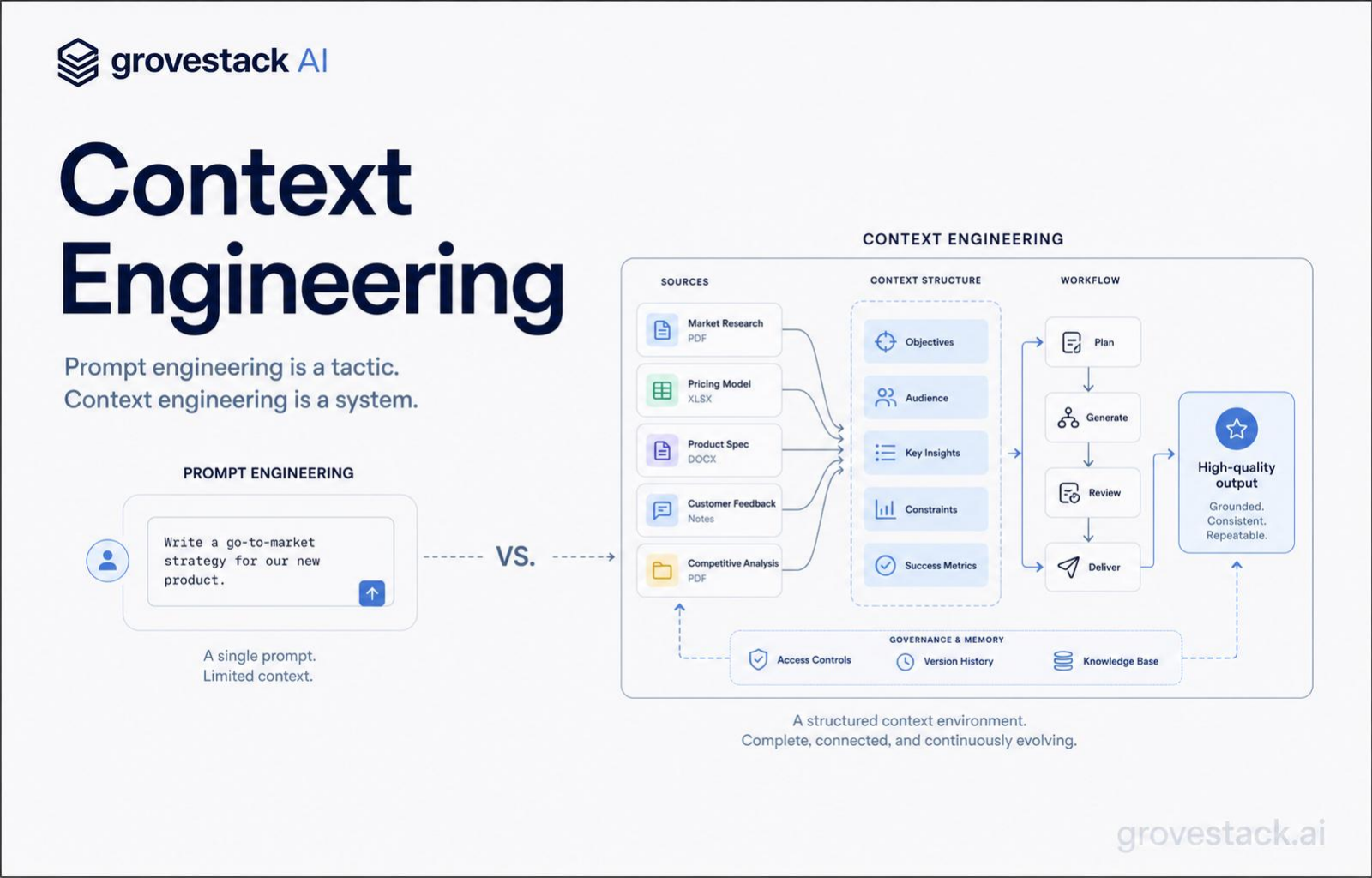
Prompt engineering is crafting clever instructions — one prompt at a time, one developer at a time. Context engineering is designing what the model sees across every operation: which information, in what structure, assembled how.
One is a search query. The other is a research methodology.
If the model gets the wrong files, the wrong requirements, or too much noise, no clever prompt will rescue the result. The model is not failing because the prompt was insufficiently clever. It is failing because the context window — the finite slice of input the model attends to before generating output — was filled with the wrong material. Cleverness at the prompt layer cannot compensate for noise at the context layer.
The teams that have figured this out stopped tuning prompts and started engineering context. The shift is not subtle. It changes who does the work, what tools the work requires, and which artifacts the organization treats as load-bearing. Prompt-engineering organizations have a folder of one-off prompts that someone, somewhere, found to work for some task. Context-engineering organizations have an infrastructure that decides — automatically, repeatably, and inspectably — what every AI operation gets to see.
Why context is the bottleneck
A coding agent has access to tools. It can read files, search code, query databases, fetch documentation. But raw access is not the same as relevant context. A medium codebase exceeds any usable context window. A knowledge base might hold millions of documents. The agent cannot process all of it at once, and even when the window is large, attention degrades when the window is full of noise.
Module 1 of any modern AI engineering curriculum teaches the same lesson the research has confirmed for years: attention is a finite resource. The model divides its attention across everything in its context window, and the quality of output depends directly on the relevance of what occupies that window. Irrelevant tokens dilute attention. Relevant tokens focus it. Liu et al. (2023) demonstrated the "lost in the middle" phenomenon — models attend strongly to information at the beginning and end of their context but degrade significantly on material placed in the middle. Order matters, not just content. More context does not automatically mean better output.
Give an agent the three files that matter and it produces precise, targeted work. Give it thirty files because you were not sure which three mattered, and it produces a generic implementation that references none of your project's conventions specifically — correct in structure, wrong in every detail that depends on knowing your code. Give it nothing and it hallucinates an API that does not exist.
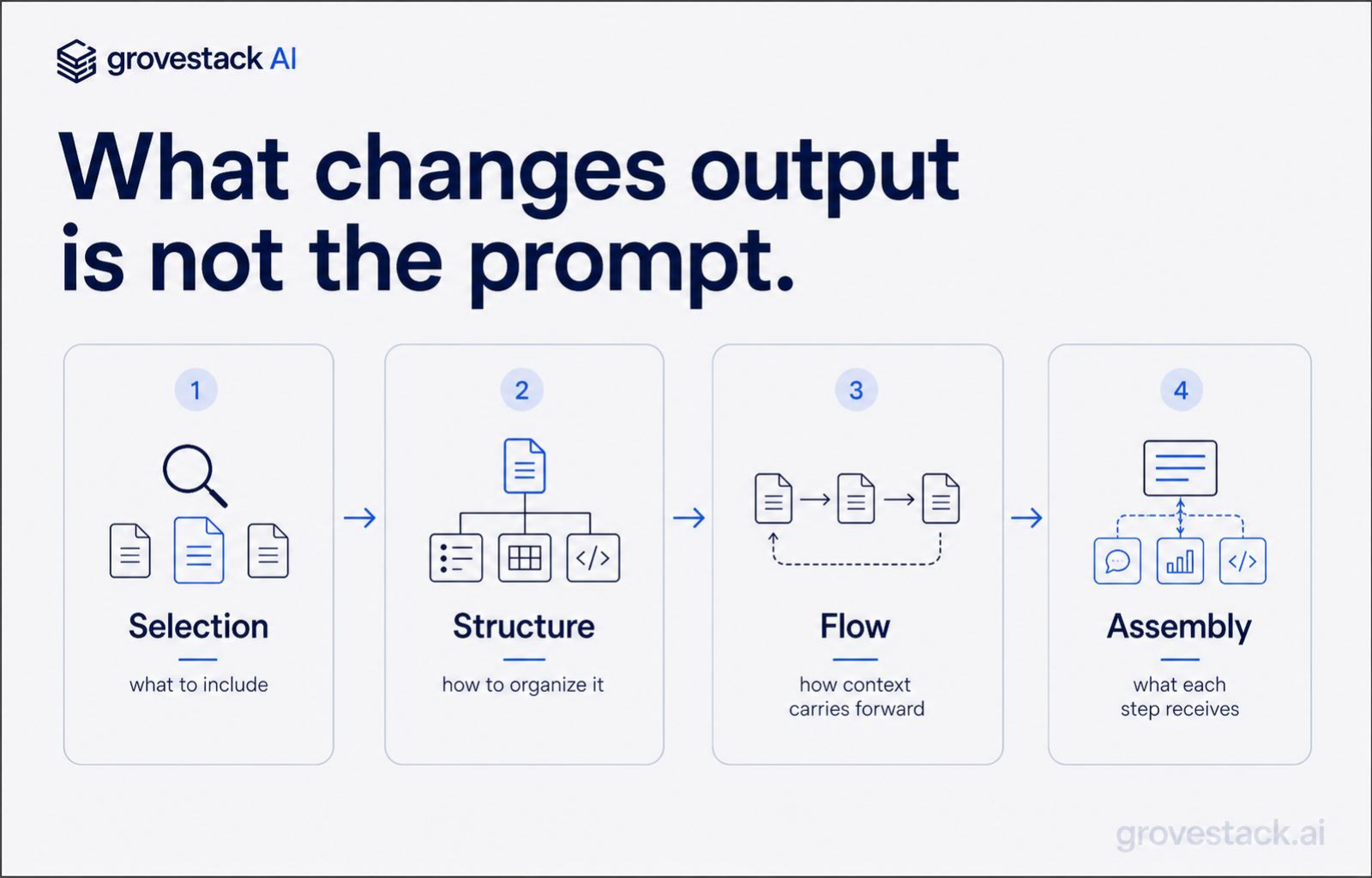
The bottleneck in agent-driven development is not capability. It is what you put in front of the agent. That is the discipline context engineering is named after. Selection of what to include is one of its concerns. It is not the only one.
The four concerns
Context engineering has four concerns, and a system that addresses only some of them produces inconsistent results.
Selection. Which files, specs, and documentation enter the window for this operation, and which do not. Selection is the part most teams understand intuitively. It is also where most teams stop. They write a prompt that names a few files, paste them in, and call it good. That works for one developer doing one task. It does not scale to a team running hundreds of agent operations a day, because every developer makes selection decisions slightly differently and the selections drift over time as the codebase changes. Selection has to be a function the system computes, not a habit a developer maintains.
Structure. How the selected information is organized once it enters the window. Structure is where the lost-in-the-middle problem lives. Critical information at the top of a 100K-token block gets attended to. The same information buried in the middle gets effectively ignored. Structure is also where contracts go: the specification at the front, the relevant codebase next, the acceptance criteria at the end. Structure is not formatting. It is the order and shape that determines which parts the model actually weights.
Flow. How information carries across multi-step workflows without loss. A single agent operation gets one window. A workflow — register, delegate, gather, validate, route, ship — has many. The output of step one is the input of step two, but only the parts that matter for step two should carry forward. Flow is how a workflow stays coherent across agents that each have their own scoped view. Without flow control, every step starts cold and the system drifts as accumulated context diverges from the current problem state. With it, every step inherits exactly what it needs from the steps before it.
Assembly. How each operation automatically receives exactly the inputs it needs. Assembly is the part that converts the first three concerns from a manual practice into infrastructure. A prompt-engineering team assembles context by hand, every time, with the developer holding the entire selection-structure-flow problem in their head. A context-engineering team has an assembly layer that does this work as a function: given the current task and the agent role, produce the right window. The developer does not assemble. The system assembles, and the developer reviews what the system produced.
The four concerns are not independent. Selection drives structure, because what you choose to include changes what fits and how it should be ordered. Structure drives flow, because how step one's window is shaped determines what step two can extract from it. Flow drives assembly, because the assembly layer has to know how downstream steps will use upstream output. A team that addresses any one concern in isolation makes the others worse. A team that designs all four together gets a context system.
What the harness automates
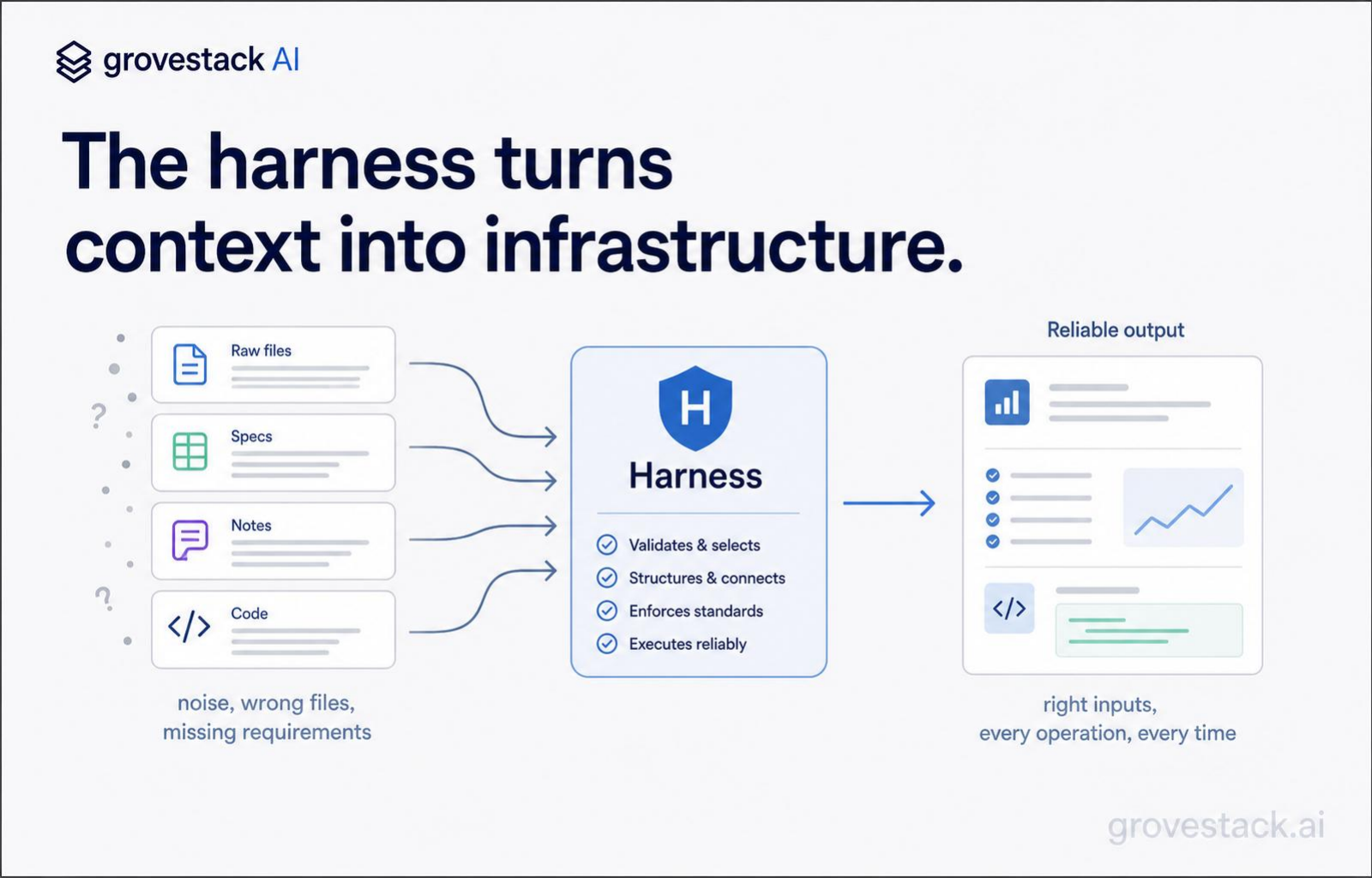
The harness is the engineered substrate around the model — specifications, validation, orchestration, and context assembly — that turns probabilistic output into production-grade software. Context engineering is the slice of the harness that lives between the agent and the corpus of everything the organization knows.
Inside the harness, context assembly is not a one-time optimization. It is infrastructure that runs every time an agent runs. The infrastructure has parts. There is a parsing layer that converts documents — code, specs, ADRs, runbooks, prior outputs — into processable units. There is an embedding layer that converts those units into searchable representations. There is a retrieval layer that, given the current task, returns the units most relevant to it. There is a structuring layer that orders the retrieved units according to the role being assembled for. There is a flow layer that carries selected outputs forward across workflow steps. Each part is a tool. Each tool is deterministic — same input, same output. The agent's reasoning about what to query is probabilistic; the retrieval that answers the query is mathematical similarity, not model recall. That is what context engineering means concretely: probabilistic need converted into deterministic delivery, every time.
This is not a single algorithm. It is an architecture with decisions at every layer. How you chunk a document, what embedding model you use, whether you retrieve by keywords or semantics or both, how you rank and combine results, how you carry retrieved chunks across steps without re-retrieving them — every choice changes the quality of the assembled window. Two organizations using the same model can produce dramatically different output because their context assembly architectures make different choices at these layers. The model is not the differentiator. The harness is.
The teams getting value from AI are not hiring better prompt writers. They are building context systems. The investment looks different from the outside — fewer prompt-tuning experiments, more infrastructure, more attention to what the organization knows and how it is organized for retrieval. The output looks different too. Reproducibility instead of inconsistency. A new agent task runs against the same assembled context as last week's task, and produces comparable work. A new team member ships their first agent-driven feature without writing a single prompt, because the harness assembles the prompt for them.
Knowledge management is the unfashionable part
The other thing context engineering forces an organization to confront is its own knowledge management. The harness can only retrieve what is already captured. If the project's conventions live in three senior engineers' heads, the assembly layer cannot pull them into a window. If the architectural decisions are scattered across Slack threads and slide decks, retrieval cannot find them deterministically. If the spec for the feature being built is a Word doc that was last updated three sprints ago, no amount of clever assembly will produce work that matches current intent.
Context engineering converts knowledge management from a nice-to-have into a load-bearing function. The thing the organization knows has to be expressed in artifacts the harness can index. Specifications have to be canonical and current. ADRs have to exist and live in the same place. Runbooks, conventions, glossaries, and decision logs have to be written down — not because writing them down is virtuous, but because the assembly layer will produce noise instead of signal if they are not.
A one-person software company solves this problem by being one person. The institutional knowledge is in one head, and the head decides what goes into the window. That does not scale. A growing organization needs the same institutional knowledge to be available to dozens of agent operations a day, and the only way to make it available at that throughput is to externalize it. The unfashionable, slow, never-prioritized work of writing things down becomes the work that makes the harness possible.
This is also why most AI initiatives stall at the demo stage. The demo runs against a hand-curated context window assembled by the lead engineer. Production runs against whatever the assembly layer can pull from the corpus. If the corpus is thin, sparse, or stale, the production window is too. The leverage that the harness produces is bounded by the corpus the organization has invested in. Teams that have done the knowledge management work get reliable agents. Teams that have not get demos.
The diagnostic question
Pick the most autonomous agent operation you currently run. Trace the input to it. Is the context the agent sees produced by a function the system computes — or is it produced by a developer pasting things into a prompt window?
If it is produced by a function, ask whether the function addresses all four concerns. Is selection encoded as a query against an indexed corpus, or is it a hardcoded list of files? Is structure ordered to put critical content where attention is strongest, or does it just dump material in some default order? Does flow carry across steps, or does each step start cold? Does the assembly run automatically for every operation, or only when a developer remembers to run it?
If most of the answers are "no," your AI investment is sitting on a prompt-engineering substrate, and the organization will continue to see exactly the kind of variance and demo-quality output that makes the model look unreliable. The model is not the problem. The substrate is.
If you do not know who in your organization owns the answers to those questions, that is the more important finding. Context engineering is a system, and systems have owners. In a one-person software company, the founder owns it. In a hundred-person company, the architect-CEO owns it — the role that decides what the harness looks like and what the agents are allowed to operate against. Without an owner, the four concerns get distributed informally across whoever happens to be wiring up the next agent task, and the assembly layer that should be infrastructure becomes whatever each developer pastes into the prompt window today.
The teams shipping reliable AI work are not the ones with better prompts. They are the ones whose AI lives inside an environment that was designed.
Who on your team owns the environment your AI thinks inside?