

One AI agent is a tool.
Five agents without coordination is a meeting with no agenda.
The difference between a tool and a workforce is infrastructure. Multiple agents can review code, generate tests, analyze security, and validate output simultaneously, at machine speed, with zero ego. But only if the harness defines who does what, in what order, with what handoffs.
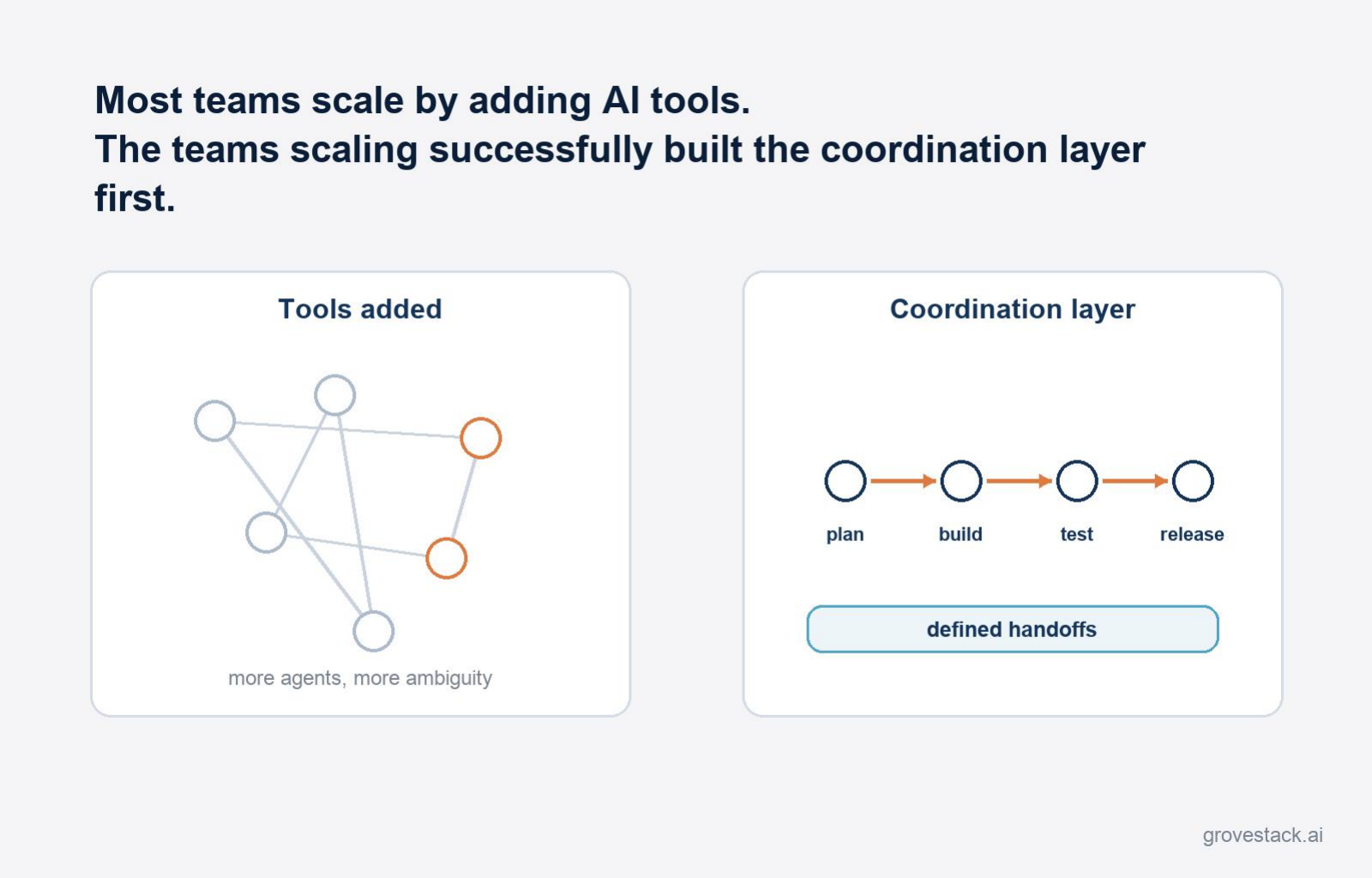
Most teams try to scale AI by adding more agents on top of the existing workflow. They discover, usually after a few weeks of declining output quality, that more agents do not produce more leverage. They produce more chaos. The chaos is not because the models are bad. It is because the workflow that was implicit when one engineer ran one agent stops working the moment two agents touch the same problem. The chaos is structural. It is solved structurally.
The teams scaling successfully built the coordination layer first.
What happens without coordination
The failure mode is concrete and easy to reproduce. Two agents work on the same codebase. Agent A analyzes requirements and decides the system needs a UserService class with create_user and authenticate methods. Agent B, working independently from a different slice of the spec, also creates a UserService — with register and login methods. Neither agent knows about the other's work. Both write their files. The codebase now has two conflicting implementations of the same concept, with different signatures and incompatible authentication assumptions.
A human reviewer reads both, understands the intent behind each, decides which to keep, and rewrites everything that depends on the discarded version. The agents did their individual jobs correctly. The system failed because nothing connected them.
That is the mildest failure mode. The next-mildest is duplication: two agents redo the same work because neither can discover that the other already did it. Past that, contradictions: outputs that disagree with each other in ways no single agent can resolve. Past that, silent loss: information produced by one agent that never reaches the agent that needed it, because nothing in the system was responsible for moving it. Past that, the human becomes the coordination layer — reading output from one agent, copying relevant parts into the prompt of another, resolving conflicts by hand. Which is exactly the unstructured chat-window pattern the harness was supposed to replace, just with more steps.
Wooldridge's foundational textbook on multi-agent systems catalogs decades of research showing the same lesson at every scale at which agents have ever been deployed: coordination is not optional, and ad-hoc coordination collapses. The research is older than coding agents. The lesson is not.
The new wrinkle is that human teams used to fall back on informal communication when the protocols broke. Slack message, hallway conversation, tap on the shoulder. Coding agents cannot. Every coordination failure in an agent system is a silent failure. No one raises a hand. No one asks a clarifying question. The system produces wrong output, and the operator does not notice until the damage is downstream.
The three concerns
A coordination layer that works has to solve three problems independently of the number of agents or the type of work.
Discovery answers: who is available? Before an orchestrator can assign work, it must know which agents exist, what capabilities they have, and whether they are currently operational. Without discovery, the system either hardcodes agent assignments — brittle — or broadcasts every task to every agent — wasteful. A registry of agents, with capability declarations, is what discovery looks like in production. New agents register on startup. Failed agents drop out. The orchestrator queries the registry to decide who can do the next step.
Messaging answers: what do agents share? When one agent finishes a step and the next agent needs the result, the messaging protocol determines the format, delivery guarantees, and routing of that information. Structured messages with explicit fields for topic, payload, sender, and correlation identifiers are the unit of coordination. Schemas validate. Messages deliver or fail. There is no approximate routing, no probabilistic delivery, no informal hand-off where the receiving agent has to parse a natural-language summary and hope nothing was lost. The agents reason probabilistically. The protocol between them is deterministic.
Delegation answers: who owns this work? Each task has a single owner at any time. Work is assigned with explicit inputs, outputs, acceptance criteria, and a bounded scope. If the owner fails — model error, timeout, contract violation — the task is reassigned automatically rather than dropped. The orchestrator tracks ownership the way an engineering manager tracks who is on which ticket, except the orchestrator does it through structured records rather than memory.
When the three concerns are addressed structurally, the surface area of the system stops scaling chaotically with the number of agents. Adding a sixth or sixteenth agent is a registration event. Routing the next task to the new agent is a discovery query. Delivering its inputs is a typed message. Tracking its work is a delegation record. The orchestrator's complexity stays bounded because the rules are structural.
What "process becomes enforceable" actually means
The line worth holding is that the harness does not negotiate. A human team might skip code review when the deadline is tight. The harness never skips it. Process that lives in a wiki is a suggestion. Process that lives in the harness is a guarantee.
Concretely, this looks like four properties that hold across every workflow.
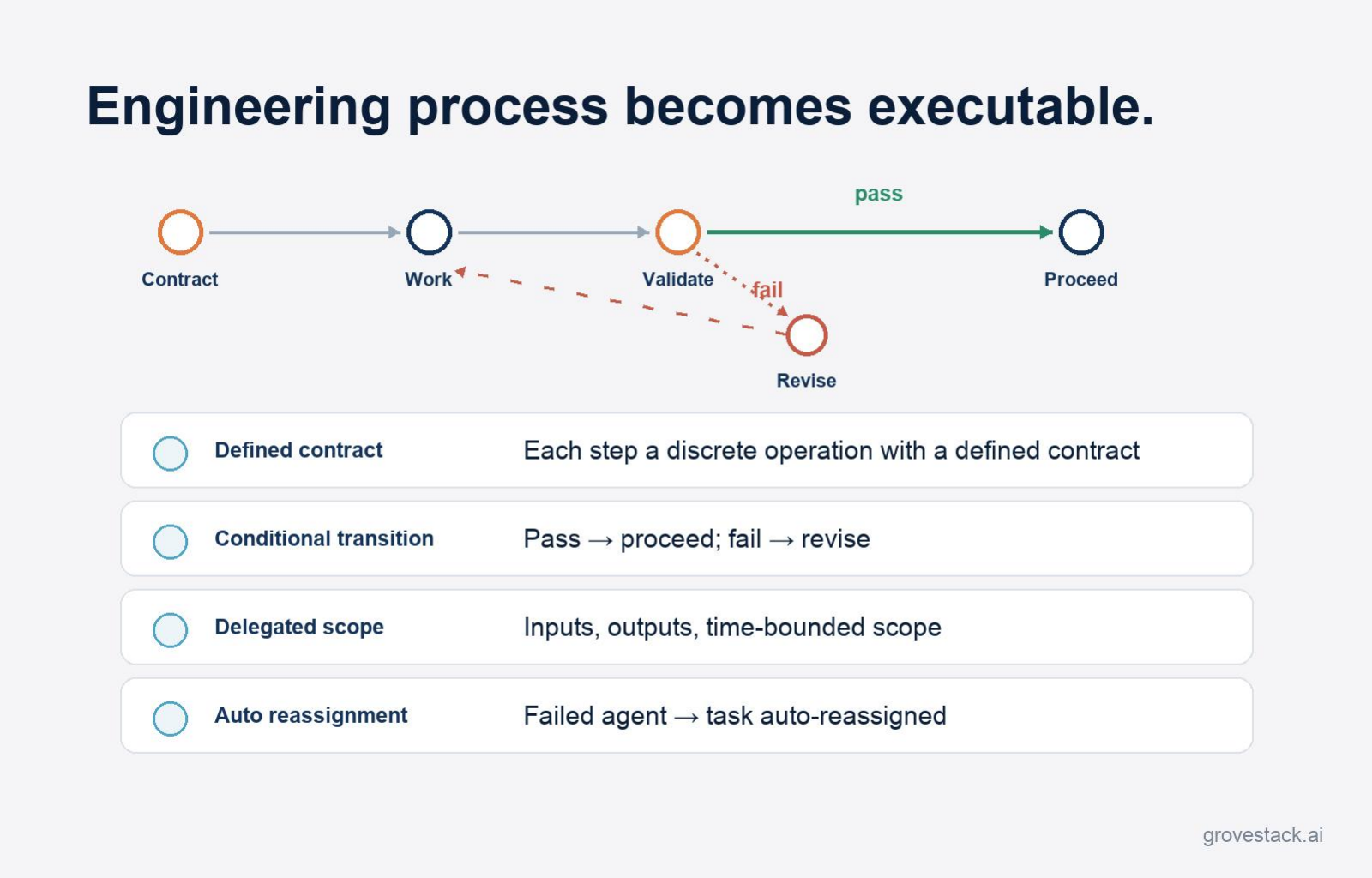
Each step is a discrete operation with a defined contract. The step has an input schema, an output schema, and validation rules. It either produces output that satisfies the schema or it fails. There is no partial output that gets through because the next agent figured out what was probably meant. The contract is the boundary, and the boundary is enforced.
Transitions between steps are conditional, and the condition is mechanical. If the tests pass, the workflow proceeds to deploy. If they fail, the workflow loops back to the agent that produced the bad output, with the failure as input. The decision is not made by an engineer who decides whether the failure is "real" or "flaky." The decision is made by the harness against a rule the team wrote down. Flakiness gets fixed at the rule level, not at the moment-of-decision level.
Work is delegated with clear inputs, outputs, and time-bounded scope. The agent receives exactly what it needs to do its job and is responsible for producing exactly what the next step requires. If it cannot, the delegation record carries that information forward, and the orchestrator routes accordingly. Scope cannot drift mid-step because the contract was set at delegation time.
If an agent fails, the task is reassigned automatically. Failure is a structured event the orchestrator handles. Either the same task goes to a different agent, or the workflow surfaces the failure to a human gate that was always part of the design. There is no orphan task that quietly sits in some agent's history because nobody wrote the reassignment logic.
The discipline this produces is exactly the discipline that human teams have wanted and largely failed to maintain. Code review skipped at 4:55 on Friday. Tests deferred because the build was already red. The pre-deploy security check that "we'll catch in the next sprint." Process erodes under pressure because the system that enforces process is human, and humans negotiate.
The harness does not negotiate. AI agents cannot improvise around missing process. That is the feature, not the limitation. It forces the discipline that human teams abandon under deadline pressure, and it forces it without anyone needing to argue the case in a stand-up.
Coordination is leadership work
It is tempting to read this as a purely technical problem — wire up a message bus, define some schemas, ship the registry. The mechanics are technical. The decisions are not. Someone has to decide which agents exist, what capabilities each agent declares, what handoffs are valid, what gates fire when, what failure modes route where, and what scope each step is allowed to operate against. Those are workflow design decisions. They are identical, in shape, to the decisions an engineering manager has always made about who does what, in what order, with which review gates.
In a one-person software company, this is the founder making process decisions and writing them down. In a hundred-person company adopting agents, it is the architect-CEO function — the role that sits where the engineering manager used to sit, but operates at the layer where the workflow is defined rather than at the layer where the work is implemented. The engineering manager's coordination skills do not become obsolete. They move up a level. The team being coordinated is a registry of agents instead of a roster of engineers, but the operation is the same.
This is also why workflow tooling — durable execution engines, message buses with typed schemas, agent registries with capability indexes — has moved to the center of the stack. None of that infrastructure is glamorous. It is the substrate the architect-CEO uses to manage a team of agents the way an engineering manager would use Linear and Slack to manage a team of humans. Different infrastructure, same operation.
The teams that have figured this out are not faster because their agents are smarter. They are faster because the coordination overhead — the part that used to live in standups, sidebars, and informal hallway alignment — has moved into the harness, where it is structured, observable, and consistent. The same overhead, executed by the system rather than by the humans, produces leverage that the humans-in-a-room model never could.
The diagnostic question
Pick the most consequential AI workflow you currently run. Ask three questions about it.
Can the orchestrator name, without any human input, every agent that participates and every capability each one declares? If the answer requires checking with the engineer who set it up, discovery is implicit, and the workflow is brittle to staff changes.
Can every handoff between steps be inspected as a structured message — sender, recipient, payload, correlation ID, schema — without parsing freeform text? If handoffs are happening through prompts cut-and-pasted between agent contexts, messaging is unstructured, and information is being lost silently.
If a step fails right now, what happens? If the answer is "we'd notice eventually" or "the engineer would re-run it," delegation is informal, and the system has no model of who owns what when work breaks. The next failure will produce the same scramble as the last one.
When all three answers are structural — registry, typed messages, automatic reassignment — the workflow can scale. New agents plug in by registering. New steps slot into the graph by declaring their contract. The team adds capacity without adding chaos. When the answers are informal, every new agent makes the system more fragile, and the productivity gains the leadership team expected from "more AI" are silently consumed by the coordination tax.
Can your engineering process run without someone remembering the next step?